
ZooKeeper
ZooKeeper:分散式應用程式的分散式協調服務
ZooKeeper 是一個分散式、開放原始碼協調服務,用於分散式應用程式。它公開了一組簡單的原語,分散式應用程式可以建構在這些原語之上,以實作用於同步、組態維護、群組和命名的高階服務。它被設計為易於編寫程式,並使用類似於檔案系統中常見目錄樹結構的資料模型。它在 Java 中執行,並同時具備 Java 和 C 的繫結。
協調服務出了問題時,通常很難解決。它們特別容易發生競爭條件和死結等錯誤。ZooKeeper 背後的動機是減輕分散式應用程式從頭實作協調服務的責任。
設計目標
ZooKeeper 很簡單。ZooKeeper 允許分散式程序透過一個共用階層式命名空間進行協調,其組織方式類似於標準檔案系統。命名空間包含資料暫存器(在 ZooKeeper 術語中稱為 znode),它們類似於檔案和目錄。與專為儲存而設計的典型檔案系統不同,ZooKeeper 資料會保留在記憶體中,這表示 ZooKeeper 可以達到高吞吐量和低延遲的數字。
ZooKeeper 實作非常重視高效能、高可用性和嚴格順序存取。ZooKeeper 的效能面向表示它可以用於大型分散式系統。可靠性面向防止它成為單點故障。嚴格順序表示可以在用戶端實作複雜的同步原語。
ZooKeeper 是複制的。與它協調的分散式程序一樣,ZooKeeper 本身也打算複製在稱為整體的眾多主機上。
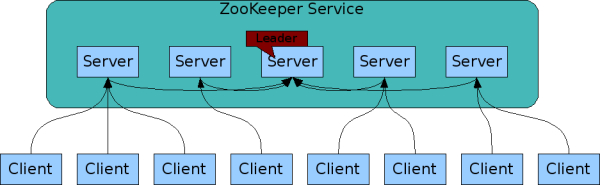
組成 ZooKeeper 服務的伺服器必須彼此知道。它們維護一個狀態的記憶體映像,以及永久儲存空間中的交易記錄和快照。只要大多數伺服器可用,ZooKeeper 服務就會可用。
用戶端連線到單一 ZooKeeper 伺服器。用戶端會維持一個 TCP 連線,透過此連線傳送要求、取得回應、取得監控事件,以及傳送心跳。如果與伺服器的 TCP 連線中斷,用戶端將會連線到其他伺服器。
ZooKeeper 是順序的。ZooKeeper 會為每個更新加上一個數字,以反映所有 ZooKeeper 交易的順序。後續作業可以使用順序來實作較高層級的抽象,例如同步原語。
ZooKeeper 很快速。在「讀取主導」的工作負載中特別快速。ZooKeeper 應用程式會在數千台機器上執行,而且在讀取比寫入更常見的情況下執行效果最佳,比例約為 10:1。
資料模型和階層式命名空間
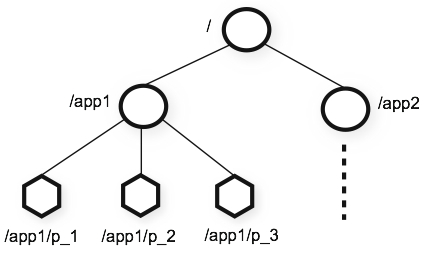
ZooKeeper 提供的命名空間很像標準檔案系統的命名空間。名稱是路徑元素的序列,各元素以斜線 (/) 分隔。ZooKeeper 命名空間中的每個節點都以路徑識別。
ZooKeeper 的階層式命名空間
節點和暫時節點
與標準檔案系統不同,ZooKeeper 命名空間中的每個節點都可以有資料與子節點關聯。這就像有一個檔案系統允許檔案同時也是目錄。(ZooKeeper 是設計來儲存協調資料:狀態資訊、組態、位置資訊等,因此儲存在每個節點的資料通常很小,在位元組到千位元組的範圍內。)我們使用術語znode來清楚說明我們正在討論 ZooKeeper 資料節點。
Znode 會維護一個 stat 結構,其中包含資料變更、ACL 變更和時間戳記的版本號碼,以允許快取驗證和協調更新。每次 znode 的資料變更時,版本號碼就會增加。例如,每當用戶端擷取資料時,也會收到資料的版本。
儲存在命名空間中每個 znode 的資料會以原子方式讀取和寫入。讀取會取得與 znode 關聯的所有資料位元組,而寫入會取代所有資料。每個節點都有存取控制清單 (ACL),用來限制誰可以做什麼。
ZooKeeper 也有短暫節點的概念。這些 znode 會存在於建立 znode 的工作階段處於活動狀態的時間內。當工作階段結束時,znode 會被刪除。
條件式更新和監控
ZooKeeper 支援監控的概念。客戶端可以在 znode 上設定監控。當 znode 發生變更時,監控會被觸發並移除。當監控被觸發時,客戶端會收到一個封包,說明 znode 已變更。如果客戶端與其中一個 ZooKeeper 伺服器的連線中斷,客戶端會收到一個本機通知。
3.6.0 新功能:客戶端也可以在 znode 上設定永久性的遞迴監控,這些監控不會在觸發時被移除,而且會觸發註冊 znode 以及任何子 znode 的遞迴變更。
保證
ZooKeeper 非常快速且簡單。不過,由於其目標是作為更複雜服務(例如同步)的建構基礎,因此它提供了一組保證。這些保證包括
- 順序一致性 - 來自客戶端的更新會按照它們被傳送的順序套用。
- 原子性 - 更新會成功或失敗。沒有部分結果。
- 單一系統映像 - 客戶端會看到服務的相同檢視,無論它連線到哪個伺服器。亦即,即使客戶端使用相同會話故障轉移到不同的伺服器,它也永遠不會看到系統的舊檢視。
- 可靠性 - 一旦更新套用,它就會從那時起持續存在,直到客戶端覆寫更新為止。
- 及時性 - 客戶端對系統的檢視保證在某個時間範圍內是最新的。
簡單的 API
ZooKeeper 的設計目標之一是提供一個非常簡單的程式設計介面。因此,它只支援這些作業
-
建立:在樹狀結構中的位置建立節點
-
刪除:刪除節點
-
存在:測試節點是否存在於某個位置
-
取得資料:從節點讀取資料
-
設定資料:將資料寫入節點
-
取得子節點:擷取節點的子節點清單
-
同步:等待資料傳播
實作
ZooKeeper 元件顯示 ZooKeeper 服務的高階元件。除了要求處理器之外,組成 ZooKeeper 服務的每個伺服器都會複製其自己每個元件的副本。
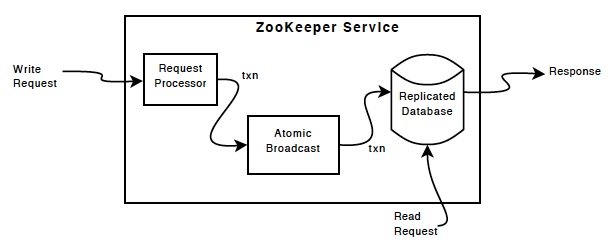
複製資料庫是一個內存資料庫,包含整個資料樹狀結構。更新會記錄到磁碟以利復原,而且寫入會在套用到內存資料庫之前序列化到磁碟。
每個 ZooKeeper 伺服器都會服務用戶端。用戶端會連線到一個伺服器來提交要求。讀取要求會從每個伺服器資料庫的本機複本中提供服務。會變更服務狀態的要求(寫入要求)會由協議協定處理。
作為協議協定的一部分,所有來自用戶端的寫入要求會轉發到一個稱為領導者的單一伺服器。其餘的 ZooKeeper 伺服器(稱為追隨者)會從領導者那裡收到訊息提案,並就訊息傳遞達成共識。訊息層會負責在發生故障時替換領導者,並將追隨者與領導者同步。
ZooKeeper 使用自訂原子訊息傳遞協定。由於訊息層是原子的,因此 ZooKeeper 可以保證本機複本絕不會分歧。當領導者收到寫入要求時,它會計算寫入套用時系統的狀態,並將其轉換成擷取此新狀態的交易。
用途
ZooKeeper 的程式設計介面經過刻意簡化。不過,您可以使用它來實作較高階的作業,例如同步原語、群組成員資格、擁有權等。
效能
ZooKeeper 的設計目的是要具有高效率。但事實上是如此嗎?Yahoo! Research 的 ZooKeeper 開發團隊的結果顯示,的確如此。(請參閱 ZooKeeper 吞吐量隨讀寫比率而異。)在讀取多於寫入的應用程式中,它的效率特別高,因為寫入涉及同步所有伺服器的狀態。(讀取多於寫入通常是協調服務的情況。)
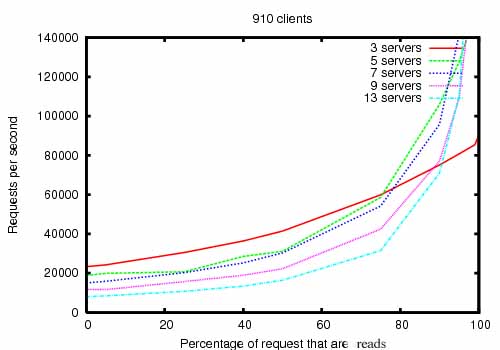
ZooKeeper 吞吐量隨讀寫比率而異 是執行於配備雙 2Ghz Xeon 和兩個 SATA 15K RPM 磁碟機的伺服器上的 ZooKeeper 3.2 版的吞吐量圖表。一個磁碟機用作專用的 ZooKeeper 日誌裝置。快照寫入到作業系統磁碟機。寫入要求為 1K 寫入,而讀取為 1K 讀取。「伺服器」表示 ZooKeeper 叢集的大小,也就是組成服務的伺服器數量。大約有 30 個其他伺服器用於模擬用戶端。ZooKeeper 叢集的組態方式為,領導者不允許用戶端連線。
註
在 3.2 版中,讀取/寫入效能比 先前的 3.1 版 提升了約 2 倍。
基準測試也指出它很可靠。在錯誤發生時可靠性顯示部署如何回應各種故障。圖中標記的事件如下
- 追隨者的故障和復原
- 另一個追隨者的故障和復原
- 領導者的故障
- 兩個追隨者的故障和復原
- 另一個領導者的故障
可靠性
為了顯示系統在故障注入時的行為,我們運行了一個由 7 台機器組成的 ZooKeeper 服務。我們運行與之前相同的飽和基準測試,但這次我們將寫入百分比保持在恆定的 30%,這是我們預期工作負載的保守比率。
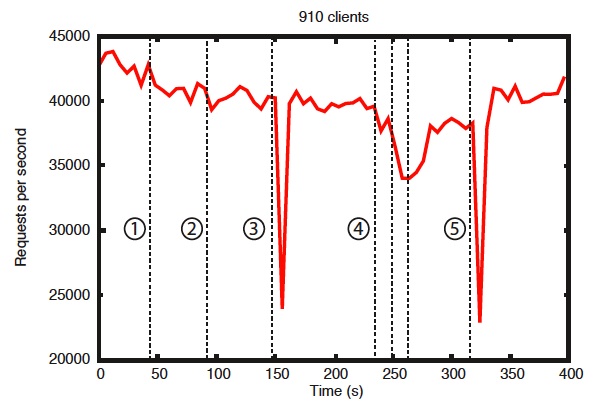
從這個圖表中有一些重要的觀察結果。首先,如果追隨者快速故障和復原,則 ZooKeeper 能夠在故障發生時維持高吞吐量。但更重要的是,領導者選舉演算法允許系統快速復原,以防止吞吐量大幅下降。根據我們的觀察,ZooKeeper 花不到 200 毫秒就能選出新的領導者。第三,當追隨者復原時,ZooKeeper 能夠在他們開始處理請求後再次提高吞吐量。
ZooKeeper 專案
ZooKeeper 已成功用於許多工業應用中。它在 Yahoo! 中用作 Yahoo! 訊息代理的協調和故障復原服務,Yahoo! 訊息代理是一個高度可擴充的發佈訂閱系統,管理數千個主題以進行複製和資料傳遞。它由 Yahoo! 爬蟲的擷取服務使用,它也管理故障復原。許多 Yahoo! 廣告系統也使用 ZooKeeper 來實作可靠的服務。
鼓勵所有使用者和開發人員加入社群並貢獻他們的專業知識。請參閱Apache 上的 Zookeeper 專案以取得更多資訊。