
ZooKeeper 內部
簡介
此文件包含 ZooKeeper 內部運作的資訊。它討論下列主題
原子廣播
ZooKeeper 的核心是一個原子訊息傳遞系統,它讓所有伺服器保持同步。
保證、屬性和定義
ZooKeeper 使用的訊息傳遞系統提供的具體保證如下
-
可靠傳遞:如果訊息
m由一個伺服器傳遞,訊息m最終將由所有伺服器傳遞。 -
總順序:如果訊息
a在訊息b之前由一個伺服器傳遞,訊息a將在b之前由所有伺服器傳遞。 -
因果順序:如果訊息
b在訊息a已由b的寄件者傳遞之後傳送,訊息a必須在b之前排序。如果寄件者在傳送b之後傳送c,則c必須在b之後排序。
ZooKeeper 訊息傳遞系統也需要有效率、可靠且易於實作和維護。我們大量使用訊息傳遞,因此我們需要系統能夠每秒處理數千個請求。雖然我們可以要求至少 k+1 個正確的伺服器傳送新訊息,但我們必須能夠從相關故障(例如停電)中復原。當我們實作系統時,我們時間不多,工程資源也很少,因此我們需要一個工程師可以存取且易於實作的協定。我們發現我們的協定滿足了所有這些目標。
我們的協定假設我們可以在伺服器之間建立點對點 FIFO 通道。雖然類似的服務通常假設訊息傳遞可能會遺失或重新排序訊息,但由於我們使用 TCP 進行通訊,因此我們對 FIFO 通道的假設非常實用。具體來說,我們依賴 TCP 的下列屬性
-
依序傳遞:資料會按照傳送順序傳遞,而訊息
m僅在m之前傳送的所有訊息都已傳遞後才會傳遞。(其推論是,如果訊息m遺失,則m之後的所有訊息都將遺失。) -
關閉後沒有訊息:一旦 FIFO 通道關閉,將不會從中收到任何訊息。
FLP 證明,如果可能發生故障,則無法在非同步分散式系統中達成共識。為了確保我們在發生故障時達成共識,我們使用逾時。但是,我們依賴時間來確保活性,而不是正確性。因此,如果逾時停止運作(例如,時鐘傾斜),則訊息傳遞系統可能會暫停,但它不會違反其保證。
在描述 ZooKeeper 訊息傳遞協定時,我們將討論封包、提案和訊息
-
封包:透過 FIFO 通道傳送的位元組序列。
-
提案:一個同意單位。提案是透過與 ZooKeeper 伺服器的法定人數交換封包來達成的。大多數提案都包含訊息,但是 NEW_LEADER 提案是一個不包含訊息的提案範例。
-
訊息:要原子廣播到所有 ZooKeeper 伺服器的位元組序列。訊息會放入提案中,並在傳遞前達成共識。
如上所述,ZooKeeper 保證訊息的總順序,並且也保證提案的總順序。ZooKeeper 使用 ZooKeeper 交易 ID (zxid) 公開總順序。所有提案在提出時都會蓋上 zxid,並準確反映總順序。提案會傳送到所有 ZooKeeper 伺服器,並在法定人數確認提案時提交。如果提案包含訊息,則訊息會在提案提交時傳遞。確認表示伺服器已將提案記錄到永久儲存空間。我們的法定人數要求任何兩組法定人數都必須至少有一個共同的伺服器。我們透過要求所有法定人數的大小為 (n/2+1) 來確保這一點,其中 n 是組成 ZooKeeper 服務的伺服器數量。
zxid 有兩個部分:epoch 和計數器。在我們的實作中,zxid 是 64 位元數字。我們使用高位元 32 位元作為 epoch,低位元 32 位元作為計數器。因為 zxid 由兩個部分組成,所以 zxid 可以表示為數字,也可以表示為一對整數,(epoch、count)。epoch 數字代表領導權的變更。每次新領導者上任時,都會有自己的 epoch 數字。我們有一個簡單的演算法,可以為提議指派唯一的 zxid:領導者只需遞增 zxid,即可為每個提議取得唯一的 zxid。領導權啟用將確保只有一個領導者使用指定的 epoch,所以我們的簡單演算法保證每個提議都會有唯一的 ID。
ZooKeeper 訊息傳遞包含兩個階段
-
領導權啟用:在這個階段,領導者會建立系統的正確狀態,並準備開始提出提議。
-
主動訊息傳遞:在這個階段,領導者會接受訊息以提出建議,並協調訊息傳遞。
ZooKeeper 是整體協定。我們不專注於個別提議,而是將提議串流視為一個整體。我們的嚴格排序讓我們能有效率地執行這個動作,並大幅簡化我們的協定。領導權啟用體現了這個整體概念。領導者只有在追隨者的法定人數(領導者也算追隨者。你隨時都可以投給自己)已與領導者同步,他們具有相同的狀態時才會變為主動。此狀態包含領導者相信已提交的所有提議,以及追隨領導者的提議,也就是 NEW_LEADER 提議。(希望你在想,領導者相信已提交的提議集合是否包含所有實際已提交的提議?答案是是。以下我們會說明原因。)
領導者啟動
領導權啟用包含領導者選舉(FastLeaderElection)。只要符合以下條件,ZooKeeper 訊息傳遞就不會在意選舉領導者的確切方法
- 領導者已看到所有追隨者的最高 zxid。
- 伺服器法定人數已承諾遵循領導者。
在兩個需求中,只有第一個,追隨者之間的最高 zxid,需要保持正確運作。第二個需求,追隨者的法定人數,只需保持高機率即可。我們將重新檢查第二個需求,因此如果在領導者選舉期間或之後發生故障並失去法定人數,我們將放棄領導者啟動並執行另一場選舉來復原。
在領導者選舉之後,單一伺服器將被指定為領導者,並開始等待追隨者連線。其餘伺服器將嘗試連線至領導者。領導者將透過傳送追隨者遺失的任何提案,或如果追隨者遺失太多提案,將傳送狀態的完整快照至追隨者,與追隨者同步。
有一個特殊情況,其中追隨者有提案 U,領導者未看見。提案依序查看,因此 U 的提案將具有高於領導者所見 zxid 的 zxid。追隨者一定在領導者選舉之後抵達,否則追隨者會被選為領導者,因為它已看到較高的 zxid。由於已提交的提案必須由伺服器法定人數查看,而選出領導者的伺服器法定人數未看到 U,因此 U 的提案尚未提交,因此可以捨棄。當追隨者連線至領導者時,領導者將告訴追隨者捨棄 U。
新領導者會取得所見最高 zxid 的世代 e,並將下一個要使用的 zxid 設定為 (e+1, 0),以建立 zxid,用於新的提案,在領導者與追隨者同步後,它將提出 NEW_LEADER 提案。一旦 NEW_LEADER 提案已提交,領導者將啟動並開始接收和發布提案。
聽起來很複雜,但以下是在領導者啟動期間的基本運作規則
- 追隨者在與領導者同步後,將確認 NEW_LEADER 提案。
- 追隨者只會確認來自單一伺服器的具有特定 zxid 的 NEW_LEADER 提案。
- 當追隨者法定人數已確認 NEW_LEADER 提案時,新領導者將提交 NEW_LEADER 提案。
- 在 NEW_LEADER 提案提交時,追隨者將提交從領導者接收的任何狀態。
- 新的領導者不會接受新的提案,直到 NEW_LEADER 提案已提交。
如果領導者選舉錯誤終止,我們不會遇到問題,因為 NEW_LEADER 提案不會提交,因為領導者不會有法定人數。當發生這種情況時,領導者和任何剩餘的追隨者將會逾時,並返回領導者選舉。
主動訊息傳遞
領導者啟動執行所有繁重的工作。一旦領導者加冕,他就可以開始發出提案。只要他仍然是領導者,就沒有其他領導者可以出現,因為沒有其他領導者能夠獲得法定人數的追隨者。如果出現新的領導者,這表示領導者已失去法定人數,而新的領導者將清除她在領導者啟動期間留下的任何混亂。
ZooKeeper 訊息傳遞操作類似於經典的兩階段提交。
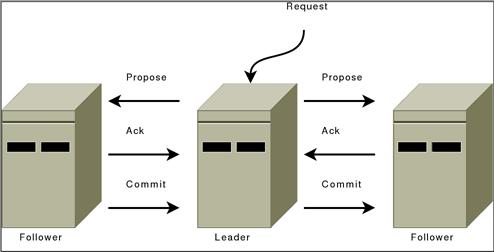
所有通訊管道都是 FIFO,所以一切都按順序完成。特別是遵守以下操作限制
- 領導者使用相同的順序向所有追隨者發送提案。此外,此順序遵循收到請求的順序。由於我們使用 FIFO 管道,這表示追隨者也會按順序收到提案。
- 追隨者按接收順序處理訊息。這表示訊息將按順序確認,而領導者將按順序從追隨者收到確認,這是因為 FIFO 管道。這也表示,如果訊息
m已寫入非揮發性儲存體,則在m之前提出的所有訊息都已寫入非揮發性儲存體。 - 只要法定人數的追隨者已確認訊息,領導者就會向所有追隨者發出 COMMIT。由於訊息按順序確認,因此領導者將按追隨者收到的順序發送 COMMIT。
- COMMIT 按順序處理。當提案提交時,追隨者會傳送提案訊息。
摘要
所以,這就是原因。為什麼它能運作?特別是,為什麼新領導者相信的一組提案總是包含任何實際上已提交的提案?首先,所有提案都有唯一的 zxid,因此與其他協定不同,我們不必擔心針對相同的 zxid 提出兩個不同的值;追隨者(領導者也是追隨者)按順序查看和記錄提案;提案按順序提交;由於追隨者一次只追隨單一領導者,因此一次只有一個活躍的領導者;新的領導者已看到來自法定人數伺服器的最高 zxid,因此已看到前一個時期的所有已提交提案;新領導者看到的來自前一個時期的任何未提交提案都將在它變得活躍之前由該領導者提交。
比較
這不只是 Multi-Paxos 嗎?不,Multi-Paxos 需要某種方式來確保只有一個協調器。我們不依賴這樣的保證。相反,我們使用領導者啟動來從領導變更或舊領導者相信他們仍然活躍中復原。
這不只是 Paxos 嗎?您的主動訊息傳遞階段看起來就像 Paxos 的第 2 階段?實際上,對我們來說,主動訊息傳遞看起來就像 2 階段提交,而不需要處理中止。主動訊息傳遞與兩者不同,在於它有跨提議排序需求。如果我們不維持所有封包的嚴格 FIFO 排序,一切都將分崩離析。此外,我們的領導者啟動階段與兩者都不同。特別是,我們使用時期讓我們可以跳過區塊未提交的提議,並且不必擔心給定 zxid 的重複提議。
一致性保證
ZooKeeper 的一致性保證介於順序一致性和線性化之間。在此部分,我們說明 ZooKeeper 提供的確切一致性保證。
ZooKeeper 中的寫入操作是線性化的。換句話說,每個寫入看起來會在客戶端發出請求和收到相應回應之間的某個時間點原子生效。這表示 ZooKeeper 中所有客戶端執行的寫入可以完全按照這些寫入的即時排序進行排序。但是,僅僅說明寫入操作是線性化的,除非我們也討論讀取操作,否則毫無意義。
ZooKeeper 中的讀取作業並非線性化,因為它們可能會傳回潛在的過時資料。這是因為 ZooKeeper 中的read 並非法定人數作業,而且伺服器會立即回應執行read 的用戶端。ZooKeeper 會這麼做,是因為它優先考量讀取使用案例的效能,而非一致性。不過,ZooKeeper 中的讀取作業具有順序一致性,因為read 作業會按順序生效,而且會尊重每個用戶端作業的順序。要解決這個問題,常見的模式是在發出read 之前發出sync。不過,這並不能嚴格保證資料為最新,因為sync 目前並非法定人數作業。舉例來說,假設兩個伺服器同時認為自己是領導者,如果 TCP 連線逾時小於syncLimit * tickTime,就有可能發生這種情況。請注意,這種情況在實際上發生不太可能,不過在討論嚴格的理論保證時,仍應將其納入考量。在這種情況下,有可能sync 會由具有過時資料的「領導者」提供服務,因此也會讓後續的read 過時。如果在read 之前執行實際的法定人數作業(例如write),則會提供較強的線性化保證。
整體而言,ZooKeeper 的一致性保證正式由順序一致性概念所擷取,或者更精確地說,是OSC(U),介於順序一致性與線性化之間。
法定人數
原子廣播和領導者選舉使用法定人數概念來保證系統的一致性觀點。預設情況下,ZooKeeper 使用多數法定人數,表示在這些通訊協定之一中發生的每次投票都需要多數票才能通過。一個範例是確認領導者提案:領導者只有在收到法定人數伺服器的確認後才能提交。
如果我們從使用多數票中擷取我們真正需要的屬性,我們只需要保證用於透過投票驗證作業(例如確認領導者提案)的程序群組在至少一個伺服器中成對相交。使用多數票可以保證此類屬性。不過,還有其他方法可以建構與多數票不同的法定人數。例如,我們可以將權重指定給伺服器的投票,並表示某些伺服器的投票較為重要。要取得法定人數,我們會取得足夠的票數,讓所有投票的權重總和高於所有權重總和的一半。
使用權重且適用於廣域部署(共置)的另一種結構是階層結構。使用這種結構,我們將伺服器分割成不相交的群組,並將權重指定給程序。若要形成法定人數,我們必須取得大多數群組 G 中的足夠伺服器,使得 G 中每個群組 g 的投票總和都大於 g 中權重總和的一半。有趣的是,這種結構能形成較小的法定人數。例如,如果我們有 9 台伺服器,我們將它們分割成 3 個群組,並將權重 1 指定給每台伺服器,那麼我們就能形成大小為 4 的法定人數。請注意,由大多數群組中的大多數伺服器組成的兩個程序子集必然具有非空交集。合理預期,大多數共置都將以高機率擁有大多數可用伺服器。
使用 ZooKeeper,我們提供使用者設定伺服器使用大多數法定人數、權重或群組階層的功能。
記錄
Zookeeper 使用 slf4j 作為記錄的抽象層。自 ZooKeeper 版本 3.8.0 起,選擇 Logback 作為記錄後端。為了提供更好的嵌入支援,未來計畫讓最終記錄實作的決定權交給最終使用者。因此,請務必在程式碼中使用 slf4j api 來撰寫記錄陳述式,但設定 logback 以在執行階段記錄。請注意,slf4j 沒有 FATAL 層級,以前的 FATAL 層級訊息已移至 ERROR 層級。如需設定 ZooKeeper 的 logback 的資訊,請參閱 記錄 部分的 ZooKeeper 管理員指南。
開發人員指南
在程式碼中建立記錄陳述式時,請遵循 slf4j 手冊。在建立記錄陳述式時,也請閱讀 效能常見問題。修補程式審查者會尋找下列事項
記錄適當層級
slf4j 中有數個記錄層級。
選擇正確的層級非常重要。依嚴重性從高到低排列
- ERROR 層級表示錯誤事件,但應用程式仍可能繼續執行。
- WARN 層級表示潛在有害情況。
- INFO 層級表示資訊性訊息,強調應用程式在粗略層級的進度。
- DEBUG 層級表示精細的資訊性事件,最適用於偵錯應用程式。
- TRACE 層級表示比 DEBUG 更精細的資訊性事件。
ZooKeeper 通常在生產環境中執行,以便將資訊層級嚴重性及更高(更嚴重)的記錄訊息輸出至記錄檔。
使用標準 slf4j 慣用語
靜態訊息記錄
LOG.debug("process completed successfully!");
然而,當需要建立參數化訊息時,請使用格式化錨點。
LOG.debug("got {} messages in {} minutes",new Object[]{count,time});
命名
記錄器應以使用它們的類別命名。
public class Foo {
private static final Logger LOG = LoggerFactory.getLogger(Foo.class);
....
public Foo() {
LOG.info("constructing Foo");
例外處理
try {
// code
} catch (XYZException e) {
// do this
LOG.error("Something bad happened", e);
// don't do this (generally)
// LOG.error(e);
// why? because "don't do" case hides the stack trace
// continue process here as you need... recover or (re)throw
}